A continuación presentamos una serie de FAQ de ayuda para el mapeador XBRL de Reporting Standard.
Pregunta: ¿Qué es el Mapeador de datos XBRL?
Respuesta: El mapeador de datos XBRL consta de dos componentes de software que le permitirán transformar datos en ambas direcciones: El Generador transforma de cualquier formato a XBRL y el Intérprete transforma de XBRL a cualquier otro formato.
Pregunta: ¿Para qué se usa mapeador XBRL?
Respuesta: El mapeador XBRL tiene dos posibles usos:
– Como Generador de informes XBRL: El mapeador accederá a datos que existen en repositorios de información y generará un informe XBRL.
– Como Intérprete de informes XBRL: El mapeador leerá un informe XBRL y cargará los datos en los destinos correspondientes.
Pregunta: ¿Cómo funcionan el Generador y el Intérprete?
Respuesta: Ambos componentes de software funcionan mediante ficheros de configuración en XML. Los ficheros de configuración permiten que los componentes se adapten a cualquier situación lo que reduce drásticamente el tiempo de realización del proyecto.
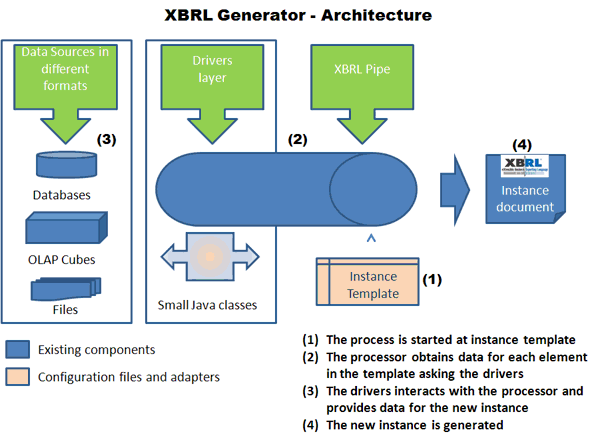 |
El generador de informesEste modulo divide su trabajo en dos fases:
|
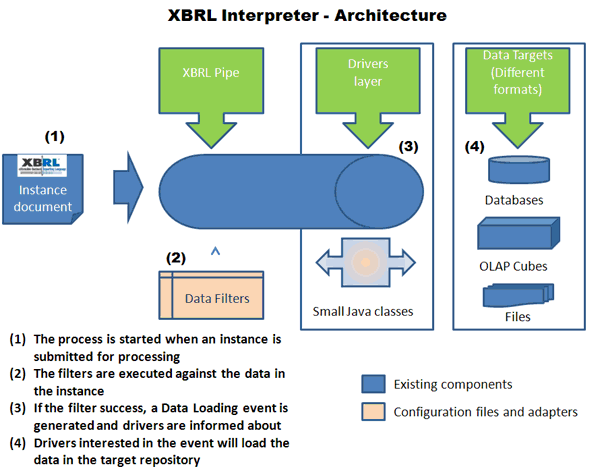 |
El intérprete de XBRLEste modulo funciona de forma similar al anterior modulo en cuanto a la arquitectura. La Fase I del intérprete comienza con una definición de filtros sobre el contenido del informe XBRL. Los filtros son independientes del dispositivo o formato final donde se cargarán los datos del informe. Cada vez que se satisfagan las condiciones del filtro se producirá un Evento de Carga.En la Fase II del Intérprete, cada Driver responderá a los eventos de carga y los datos serán almacenados en el destino final. Cada evento de carga podrá ser captado por uno o más Drivers. Los Drivers disponen de un fichero de configuración específico que permitirá al driver interactuar con el formato final |
Pregunta: ¿Qué drivers existen en la actualidad?
Respuesta: El Generador dispone de drivers para Excel, Formularios web, Bases de datos relacionales y ficheros separados por comas CSV.
El Intérprete dispone de drivers para Excel y Bases de datos relacionales.
Pregunta: ¿Se pueden desarrollar drivers nuevos?
Respuesta: Si. El desarrollo de drivers es una tarea sencilla ya que el diálogo entre el procesador y el driver está ya definido y es el mismo para cada driver.
Pregunta: ¿Qué pasa cuando cambia la taxonomía?
Respuesta: Cuando cambia la taxonomía hay que ajustar los ficheros de configuración. Reporting Estándar trabaja en el grupo de Versionado XBRL de XBRL Internacional. El objetivo de este grupo es estandarizar los formatos de los informes que documentan los cambios a las taxonomías. El Mapeador de datos XBRL de Reporting Estándar está diseñado para ajustar los ficheros de configuración a los cambios en las taxonomías y producir un informe de los cambios realizados así como aquellas áreas del proceso de migración que requieren intervención humana. Todos los cambios en las taxonomías que pueden adaptarse de forma automática son abordados por el proceso de migración de forma que se reduce el tiempo necesario para utilizar una nueva versión de una taxonomía.
Pregunta: ¿Qué otras áreas de coste son menores gracias al uso del mapeador?
Respuesta: En primer lugar, usted no necesitará ser un experto en XBRL.
En segundo lugar, el proyecto de implantación de XBRL se simplificará. Sólo será necesario configurar unos pocos componentes.
Pregunta: ¿Cuánto puede durar un proyecto de implantación de estos productos?
Respuesta: Nuestra experiencia dice que para informes de unos 200 elementos en la plantilla el tiempo total del proyecto incluyendo la formación, impantación y generación de ficheros de configuración es de unos 2 meses y 2 personas en el proyecto.
Pregunta: Soy una empresa de consultoría ¿Puedo usar sus componentes en mis proyectos?
Respuesta: Por supuesto que sí. Reporting Estándar proporciona su software para que los consultores puedan sacarle partido al estándar XBRL. Reporting Estándar no es una empresa de consultaría. Nosotros sólo desarrollamos software XBRL. Nuestro objetivo es ayudar a los consultores a que realicen con éxito los proyectos XBRL en sus clientes. Reporting Estandar estará siempre a su disposición para solucionar cualquier duda durante el proyecto.
