Reporting Estándar S.L. has developed an XBRL 2.1 Validation Engine that complies 100% with the XBRL 2.1 specification requirements.
The validation engine can be installed in the Accelerated Validation mode. In this case, the validation engine can be installed as a software component integrated to an existing infrastructure.
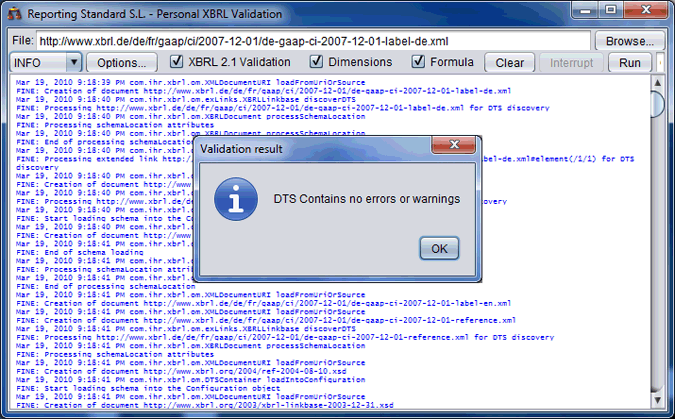 |
The component can be launched from a web page or can be used as an application without a user’s graphic interface. Accelerated Validation can be used by online validators since the validation of a 300 items report, using a 5000 items taxonomy, would only take 200 milliseconds. It is required that the taxonomy is known by the validator in advance to work in the accelerated mode.
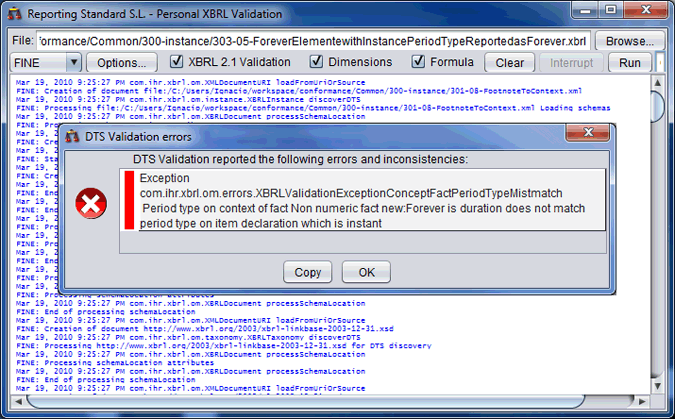 |
Making sure a validation engine passes the International XBRL Conformance Suite
XBRL International has created the conformance suite test cases to verify that XBRL processors satisfy the requirements stated by the specification. There are more than 300 different test cases covering all aspects and possible uses of XBRL.
This link prompts to a results page showing that Reporting Estándar’s validation engine passes all test cases. The page content is created automatically as each test case is executed one by one.
The results page also shows that the XBRL 2.1 validation engine created by Reporting Estándar manages all test cases according to the requirements in the documentation. All errors are detected and all valid test cases are processed accordingly. Testing to Reporting Estándar Validation Engine can be done by users, with their own computers, following these easy steps:
- Download test cases directly from XBRL International web site.
- Download the samples.jar file from Reporting Estándar’s web site.
- Review the source code for the Java class: com.ihr.xbrl.LaunchConformanceSuiteXHTML which will create the report
- Launch a Java virtual machine with parameters: -f {path to XBRL conformance suite}/conformance/xbrl.xml -m -o results.xhtml
Explanation:
The parameter -f must point to the xbrl.xml file which is the start file of the XBRL conformance suite.
The parameter -m provides information on memory usage.
The parameter -o is the name of the file to be generated by the tool. The results page will be an XHTML page and can be viewed using a web browser.
