Q: What is the XBRL Mapper?
A: The XBRL Mapper consist of a set of two software components that will allow you to transform data in two directions: The Generator transforms from any format to XBRL and the Interpreter transforms from XBRL to any other format.
Q: What are the most common uses of the XBRL Mapper?
A: The XBRL Mapper can be used: – As an XBRL Report Generator: The Mapper can access data in the internal repositories of information and generate an XBRL report. – As an interpreter of XBRL Reports: The Mapper will read the content of an XBRL report and will load the data in the data repositories.
Q: How do the Mapper components work?
A: Both software components works using configuration files written in XML. The configuration files allows the components to be used in multiple environments and permits them to be easily adapted to project needs. This feature saves project duration and implementation costs.
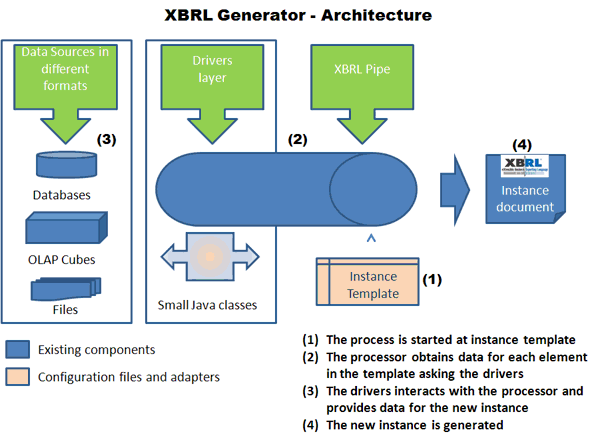 |
The Generator do its work in two phases. Phase I starts with a template of an XBRL report to be generated. Each element in the template contains information about the context to be used, the concept from the taxonomy, the data source, the unit in the case of numeric elements, etc. The template allow you map to tuple content as well and it provides you a mechanism to document how many times an element inside a tuple can occurs. The data source for each element can be configured independently within the same template. This allows you to create an XBRL instance document by combining information from an Excel spreadsheet and data from a database at the same time. The configuration file for Phase I can refer to several data sources simultaneously. Phase II consist of a pre-defined dialog between the Mapper and the Driver that obtains the data from the data source. Each Driver may use a specific configuration file if that is needed. For example, the Driver to process the content of a web form does not need a configuration file because the name of the field in the web form is used to create the correspondence between the data requests from the template file and the data submitted in the web form. But the driver for excel requires a configuration file because for each data request a cell in Excel must be specified. |
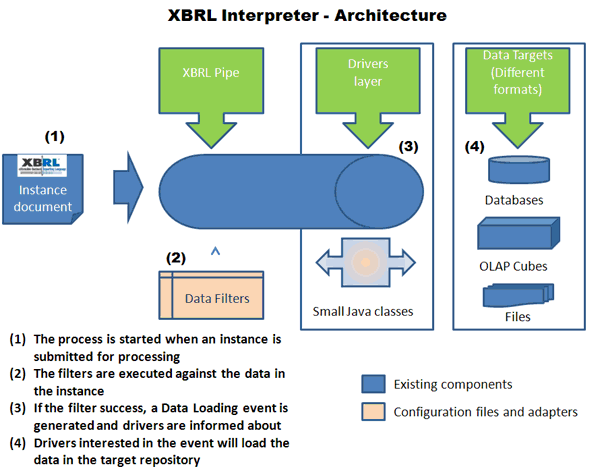 |
The Interpreter has been developed using the same architecture. During the Phase I, the interpreter starts executing a set of defined filters that operates with the data in the XBRL instance document. The filters are independent of the final data destination. At the time one filter condition is satisfied the Mapper generates a Loading event During Phase II, the Interpreter sends the Loading event to the Drivers and, in turn, the Drivers are responsible of storing the information in the final format. Each Loading Event can be handled by more than one Driver |
Q: What Drivers already exists?
A: For the Generator there are drivers for Excel, Web Forms, Relational databases, and CSV (Comma Separated Values) files.
For the Interpreter There are drivers for Excel and for Relational Databases.
Q: Can I develop a new Driver?
A: Yes, the XBRL API exposes the required interface and the configuration files allows you to select your own driver class. The development of a new Driver is pretty simple because there is just a set of methods to implement and the dialog between the processor and the driver is already defined.
Q: What happens when the taxonomy change?
A: When the taxonomy change it is necessary to change the configuration files. Reporting Estándar is working in the XBRL Versioning Working Group of XBRL International. The objective of that group is to define a standardized format to document the changes between two taxonomy versions. Reporting Estándar XBRL Mapper has been designed to automatically read the versioning reports and migrate the configuration files to adapt it to the new taxonomy version. The process of migrating the old configuration files to a new taxonomy version produces a migration report that indicates which changes can be adopted without any impact and which changes requires human intervention.
Q: What other benefits the Mapper has?
A: Firstly you don’t need to be an XBRL expert to use the Mapper.
Secondly, the project to adopt XBRL can be simplified and reduced in time because the parameterization of some existing components is easier than the development of a new project that requires XML experts learning XBRL.
Q: How long a project for using the Mapper can take?
A: In our experience, a project for implementing the mapping of 200 elements in a template considering the template design, training, components set up and generation of the configuration files is a 2 months project of 2 people.
Q: I’m a consultant, Can I use the Mapper for my own project?
A: Absolutely, Reporting Estándar provides this components to the XBRL community in general. Our most important asset is our capacity to design and build the components to facilitate the adoption of XBRL. We are not a consulting company and we prefer you to use our software in your projects, we will provide you support to your project if this is required.
